
Webで,市川駅を最寄駅とする1R(ワンルーム),1K,1DKのアパートを検索したところ,下表を得た。このデータをもとに,市川駅周辺のアパートの家賃を推定する方法を考えよう。うまい推定方法が見つかれば,格安物件をすばやく見つけることができるようになるかもしれない。
今回の例題では,目的変数を家賃として,面積(m2),築年数(年),駅徒歩分(駅まで徒歩でかかる時間(分))を説明変数にして,重回帰式を求めることにする。
重回帰分析を行う前に,各説明変数と目的変数の散布図を作成し,外れ値の有無や相関関係を視覚的に確認しておこう。
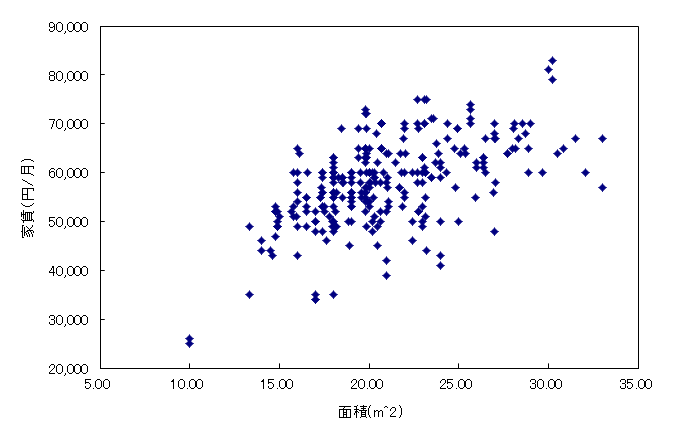
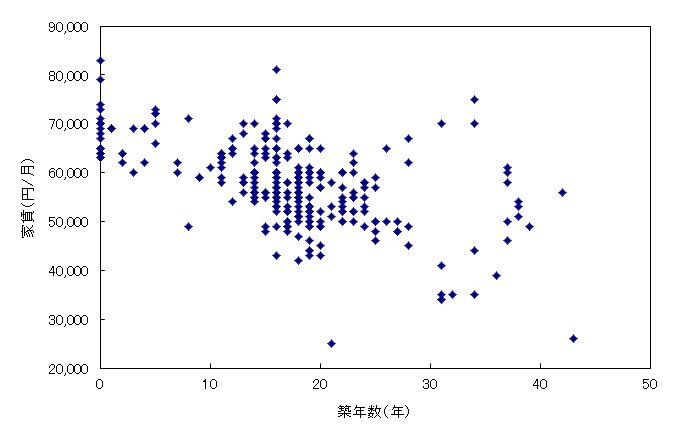
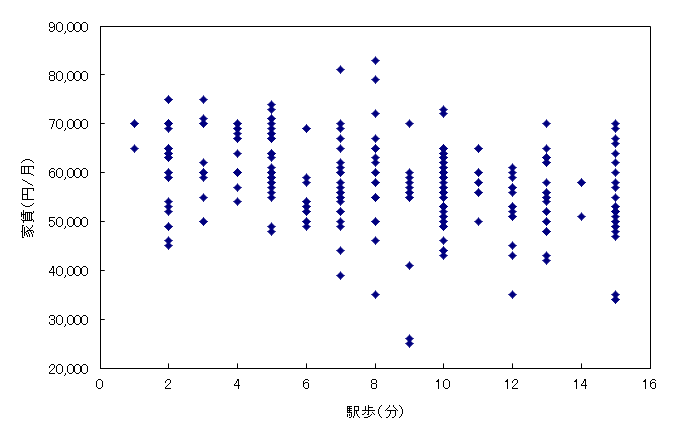
分析ツールの「相関」で相関行列を作成してみよう。
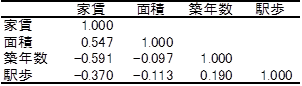
家賃と面積の間には正の相関,家賃と築年数の間には負の相関,家賃と駅歩の間には弱い負の相関が認められる。このことは想像通りであろう。
一方,説明変数同士には目立った相関は認められないことが確認できる。説明変数の間に高い相関がある場合には,うまく重回帰式を求められない場合がある。
分析ツールの「回帰分析」で回帰分析を行ってみよう。
表3〜5が得られるはずである。
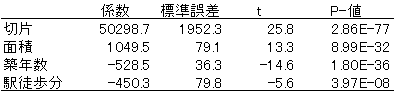

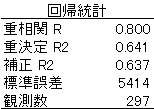
表3の係数より,推定された回帰式は
| 家賃 | = | 50299 | + | 1050×面積 | − | 529×築年数 | − | 450×駅歩 |
| (t=25.7) | (t=13.3) | (t=-14.0) | (t=-6.1) |
となることがわかる。
この係数をみると,アパートの面積が1 m2広くなると家賃は1050円高くなり,建物が1年古くなるごとに家賃が530円安くなり,駅からの距離が徒歩1分遠くなると450円安くなると見積もることができる。
例えば,現在駅から徒歩10分の築年数10年のアパートに住んでいる学生が,広さは同じくらいで,駅から徒歩5分の新築アパートに引っ越そうと考えると,毎月およそ7,500円の出費を覚悟しなければならないということになる。
回帰式の,面積の係数が最も大きいことから,面積が家賃を決定する最大の要素だと判断してはいけない。なぜなら,この係数は面積を測る単位が異なれば,当然値が変化するからである。例えば,面積のデータの単位を平方メートル(m2)から,坪(3.3m2)にしたとすれば,面積の係数は3.3倍に変化する。したがって,係数そのものを比較することはできないのである。
回帰式の下に付した括弧書きのtは,それぞれの係数のt値である。各係数のt値は,その値の絶対値が大きいほど,目的変数の予測への貢献が大きい(説明能力が高い)と判断してよい。つまり今回の解析では,最も家賃の予測に寄与しているのは,意外にも築年数である。ただし,面積と築年数のt値の絶対値は同程度であるから,面積と築年数が予測に同程度に寄与していると考えるほうが自然である。
各係数のp値は,その係数が0である(つまりその説明変数が不要である)という仮説の下で,t値が計算された値の絶対値より大きくなるような確率である。p値が(例えば0.05や0.01と比較して)大きい場合には,その説明変数をモデルに組み込む必要はないと考えればよい。ちなみに,t値が高ければ,必然的にp値が小さくなり有意性も高い。 今回の解析では,すべての係数のp値が極めて小さく,不要な説明変数は無いと判断してよい。
表4は回帰式の検定を行うための分散分析表である。この検定は,
を行っている。帰無仮説H0を換言すれば,「回帰式は無意味」ということである。
今回の解析では,有意F =8.6×10-65 < 0.01 であるから,帰無仮説H0は棄却される(つまり回帰式には意味があると考えてよい)。
重回帰分析の回帰式全体の検定が有意にならないケースは極めて稀である。よほど無関係な説明変数だけでモデルを構築したか,よほどデータ数が少ない場合に発生するくらいであろう。
表5の回帰統計量はそれぞれ次のような意味をもつ。
当面は,重決定係数 R2に注目してほしい。 今回の例題では,R2=0.64であるが,これは,面積,築年数,駅徒歩分数の3つの説明変数で家賃の分散(ばらつき)の約64%を説明できることを意味する。