研究紹介
研究領域はソーシャルメディア解析,ビッグデータ解析,異文化環境におけるソーシャルメディアマーケティング,可視化による数学教授法です.
ソーシャルメディアからの時系列トピック抽出

Twitterやブログ,ショッピングサイトの評価書込み等の時系列データから,ユーザのニーズの変遷の抽出を試みています.要素技術としては,自然言語理解分野で用いられているトピック抽出法の他に,ネットワークの階層的コミュニティ抽出法と,木の編集距離を組み合わせた方法等,マイクロクラスタリングなど,様々な手法を用いています.
近年は東日本大震災後の2億件強の Tweets や熊本地震発生後のTweets等,災害時のソーシャルメディアデータの分析に注力しています.
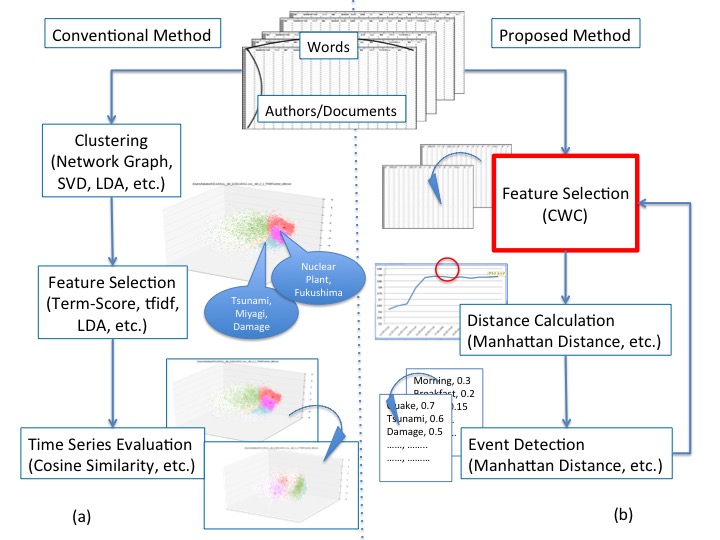
トピック抽出の従来手法にはいくつかの問題があります.まず.既存のデータマイニング技術は数千件,多くても数万件程度のデータを対象としており,数億件規模のデータに対するスケーラビリティがありません.生成されるクラスタの精度も低く,正しい情報を得られないことも多々あります.各クラスタから,その内容を説明するための特徴(重要キーワード)を抽出する必要もありますが, よく用いられるTF-IDFや term-scoreといったスコアリング手法は単語の出現頻度をベースとしており,時に本当に重要な単語を見逃してしまうことがあります.結果として,時系列上でのクラスタ間の類似度精度も低下し,正確な時系列解析を行えないといった状況にあります.
そこで本研究では,ビッグデータからより効率的にトピックを抽出するための手法の開発に取り組んでいます.特にビッグデータを解析可能な高性能な特徴抽出手法 CWCやデータの特徴を際立たせるデータ研磨と呼ばれるマイクロクラスタリング手法を利用して,これまでにないトピック抽出手法の提案・実装を試みています.デマや特徴的な話題が時系列上で発生し,拡散し,ときに変遷し,収束していくプロセスを発見・可視化する手法の開発に取り組んでいます.
提案手法では,最初に特徴選択技術 CWC を適用し,時系列上の大まかな変化を把握してから,さらに深く掘り下げていく,というアプローチを取っています.特徴選択した結果を時系列上で解析するために,特徴間の距離を測り,グラフ構造の時系列変化を追っていきます.特徴間距離が大きくなったり,グラフ構造が大きく変化したタイミングで,大きな変化が起きていると考えられ,そこを中心に詳細化していけば,イベントや話題を高精度で発掘できるのではないかと考えて研究を行っています.
さらに近年は,マイクロクラスタリング手法によりクラスタを生成し,その時系列推移を「クラスタの多様性」という観点で評価することで.話題の発生・拡散や潮目の変化,収束といったライフサイクルを表現する手法の開発に取り組んでいます.
主な共同研究
言語非依存のソーシャルメディア解析プラットフォームの構築
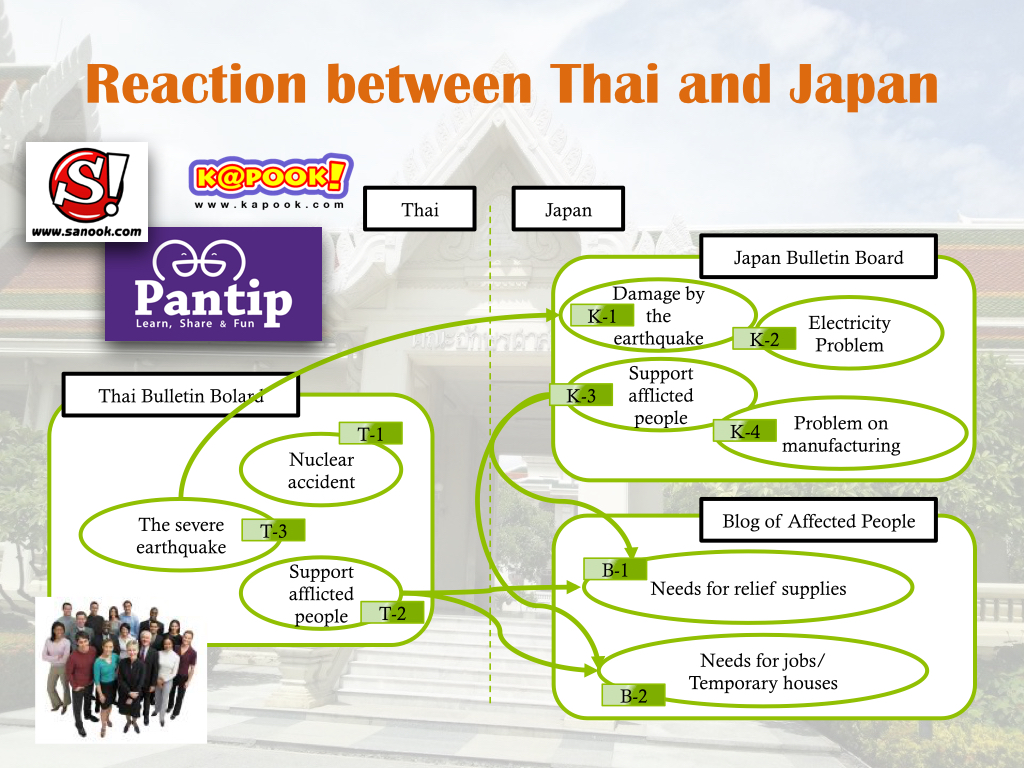
ソーシャルメディア解析を日本語のみならず,タイ語等の他言語に展開し,言語や文化の違いを考慮したソーシャルメディア解析プラットフォームの構築を目指しています.
タイ語のソーシャルメディア Sanook,Kapook,Pantip を対象として,東日本大震災後の書込みをクローリングし,言語処理を行い,トピックを抽出する試みを実施しました.日本とタイでどのような話題が発生したか,それらに関連性があるかなどを解析しています.
タイの他にインド,インドネシア等での展開も検討しています.
主な共同研究
-
学習院大学 白田研究室: 学習院大学の東洋文化研究所プロジェクトとして本研究を実施しました.
異文化環境におけるソーシャルメディアマーケティング
ファッション雑誌や漫画,日本食といった日本のコンテンツを素材として,タイ,インド,フィリピンなどのアジア諸国を中心に, Facebook等のソーシャルメディアを活用したマーケテイングを行い,異文化環境における反応の違いを解析しています.
主な共同研究
- 大日本印刷株式会社:
持続可能な社会に向けての研究
千葉商科大学学長プロジェクトの下で,持続可能な社会の実現に向けて,SDGsのコンセプトを踏まえ,USR(University Social Responsibility, 大学の社会的責任)や自然エネルギー100%大学,分散型エネルギー社会の研究を行っています.
